Emotional Embedding: Emotional Content of Words



BY- Prasant Kumar
Word Embeddings are one of the most useful tools in any modern Natural Language Processing expert’s toolkit. They contain various types of information about each word which makes them the best way to represent the terms in any NLP task. But there are some types of information that cannot be learned by these models.
Emotional Information of words is one of those.
Link to the research paper 👉 Click Here
There are many Embedding techniques used to extract the maximum information out of the text, other than Emotion from them. The authors have also mentioned many related works in brief, you can read about them in Research Paper.
Emotional Constraints in Word Vector
For fitting emotional information into pre-trained word vectors, they used a methodology that not only brought the vectors for similar words close to each other, but also moved vectors for opposite words farther apart used to incorporate additional linguistic constraints in word vector spaces.
Their main goal was to change the vector space V = {v1,v2,...,vn} to V' = {v'1,v'2,...,v'n} in a carefulmanner to add emotional constraints to the vector space without loosing too much information already present during the original learning step.
Steps to complete this Task
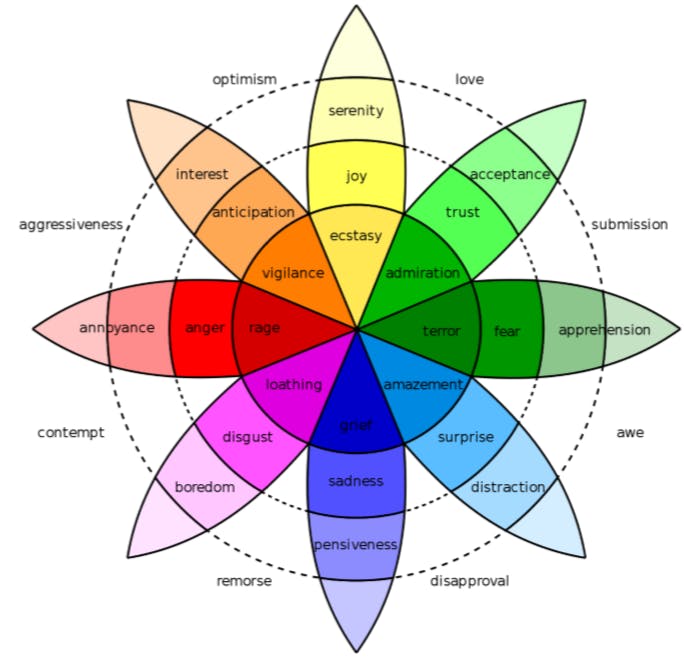
They created two sets of constraints based on NRC(Non-Commercial Research) Emotion Lexicon (list of English words with their associated basic emotion), one for words which have a positive relation to an emotion such as (abduction, sadness), and one to keep track of each words relation to the opposite of that emotion (abduction, joy), joy being the opposite of sadness.
In NRC lexicon annotated over 14k English words for eight emotions from Plutchiks model of basic emotions.
To create two constraint sets, they extracted all word/emotion relations indicated in the lexicon so that in their first set S = {(w 1 ,e 1 ),(w 1 ,e 3 ),(w 2 ,e 2 ),...} they had ordered pairs, each indicating a word and the emotion it is associated with.
And for each emotion ei, we add its opposite e'i to our second set O = {(w 1 ,e' 1 ),(w 1 ,e' 3 ),(w 2 ,e' 2 ),...} in which e'i is the opposite emotion to ei based on Plutchiks model.
We have extracted over 8k such pairs of (word, emotion)constraints from the NRC lexicon for each of the positive and negative relation sets.They defined their objective functions so that
To decrease the angular distance between similar emotions and increase the distance between the opposite emotions words:
We want the pairs of words in positive relation set to get closer together
So the objective function for positive relations would be:
P R(V') = (u,w)∈S max(0,d(V' u,V'w))
where d(v' u,v'w) is the cosine distance between the two vectors.
And we want to increase the distance between pairs of words in our negative relation set, so the objective function for the negative relations would be:
N R(V') = (u,w)∈O max(0,1−d(v' u,v'w))
We also need to make sure we lose as little information as possible by preserving the shape of our original vector space.
In order to do this, we add a third part to our objective function to make sure we are not changing the overall shape of the space by much:
V S P(V,V') = max(0,|d(v' u,v'w)−d(vu,vw)|)
For efficiency purposes, we only calculate the distance for a neighborhood of each word N(i) which includes all words within the radius distance r = 0.2 of the word. So our final objective function is the sum of all three together:
Obj(V') = P R(V') + N R(V') + V S P(V,V')
Stochastic Gradient descent was used for 20 epochs to train the vector space V and generate the new space V'.
Experiments
As we trained the model on Plutchik’s model we decided to use another emotion model for testing.
In the first experiment they assess the average in category mutual similarity of secondary and tertiary emotions in the three-level categorization of emotions.
In this model, 6 basic emotions of Liking, Joy, Surprise, Anger, Sadness, and Fear, and categorized around 140 sub-emotions under these 6 emotions in two layers. The reported numbers are the average cosine similarity of all mutual in-category emotions words.The vector spaces used here are:
• Word2Vec trained full English Wikipedia dump
• GloVe from their own website
• fastText trained with subword information on Common Crawl
• ConceptNet Number batch
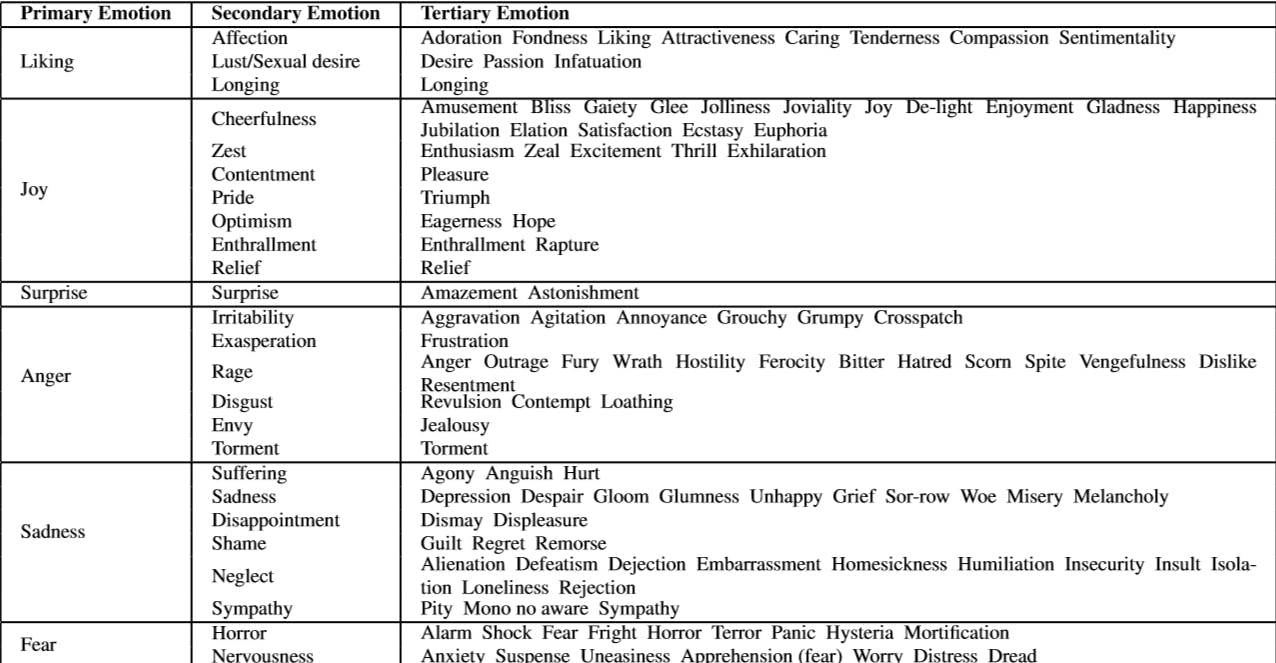
Table :👉 Three Layered Emotion Classification
- In the second experiment we assessed the performance of the model for the similarity between
opposite emotions. Again they used Shaver et al.’s categorization as their testing emotion model and calculated the mutual similarity between opposite emotion groups.
In this test, we chose two pairs of opposite emotions, Joy vs. Sadness and Anger vs. Fear. The reported numbers are average cosine similarity between each member of the opposite emotion categories.
The models perform significantly better after training with the best performance for the retrained Numberbatch in distinguishing between Anger vs. Fear and retrained Glove for Joy vs. Sadness (with Numberbatch following closely).
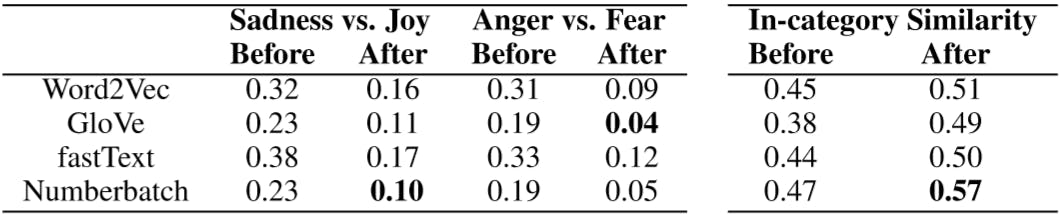
Table :👉 Left: Average similarity between opposite emotion groups. We want the similarity of opposite emotions be as close to zero az possible. After training the average similarities decrease for all models.
Right: Average of in-category mutual similarity in three layered categorization of emotions before and after emotional fitting. We wantthesimilarityofcloseemotionsbeasclosetooneaspossible. Aftertraining,averagesimilarityofin-category emotions increases for all models.
Future Work
This methodology could be improved by incorporating more complex emotional information, such as intensity of emotions and combination of emotions defined in psychological models. Training the original embeddings on corpora that are more emotionally rich might also increase the emotional sensitivity of these models.**