


Transformer was proposed in the paper - Attention is All You Need . Tensorflow implementation of it is available as a part of Tensor2Tensor. Here we will attempt to summarise all the concepts one by one to hopefully make it easier to understand to people without in-depth knowledge of the subject matter.
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU, ByteNet and ConvS2S,all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions.
In the Transformer, this is reduced to a constant number of operations, at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention (All these terms are explained below).
Using Machine Learning for translation is a Black Box model, its not particularly know to us how an algorithm translating it.

Encoder and Decoder
Here are Encoder and Decoders working to encode and Decode one language to other.
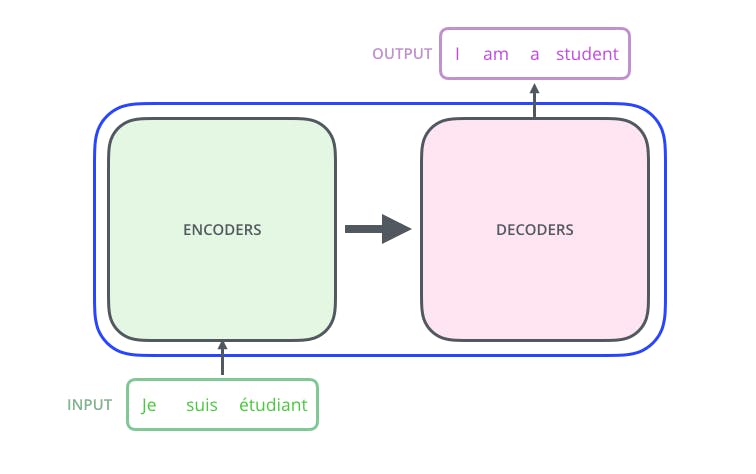
Encoder -There are 6 encoders are used for Translation one over the other (6 encoders worked best for researchers, that why 6 encoders).
Decoder -Same as encoders 6 decoders are added to decoder encoded text.
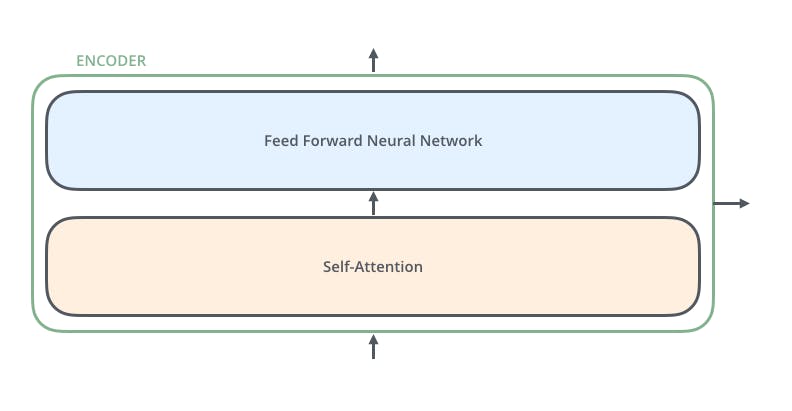
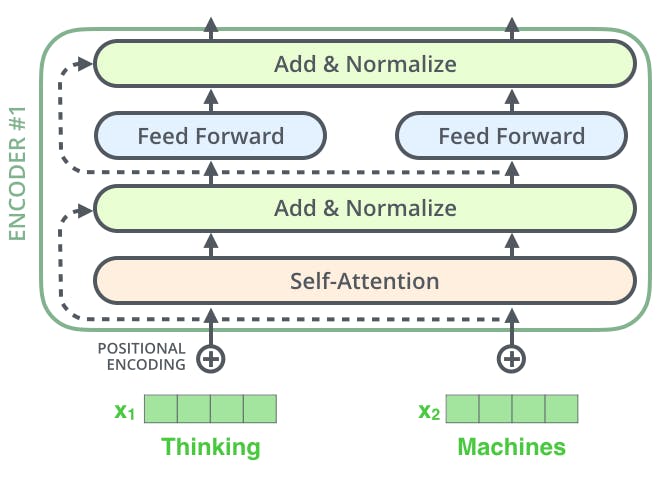
Encoders
There are two components that are working inside the Encoders
- Self-Attention
- Feed Forward Neural Network
What is Attention?
An Attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
These attention function are also of two types:
- Multi-head Attention
- Self Attention
- Multi- head Attention Instead of performing a single attention function with model-dimensional keys, values, and queries, we found it beneficial to linearly project the queries, keys, and values h times with different, learned linear projections to dq, dk and dv dimensions, respectively.
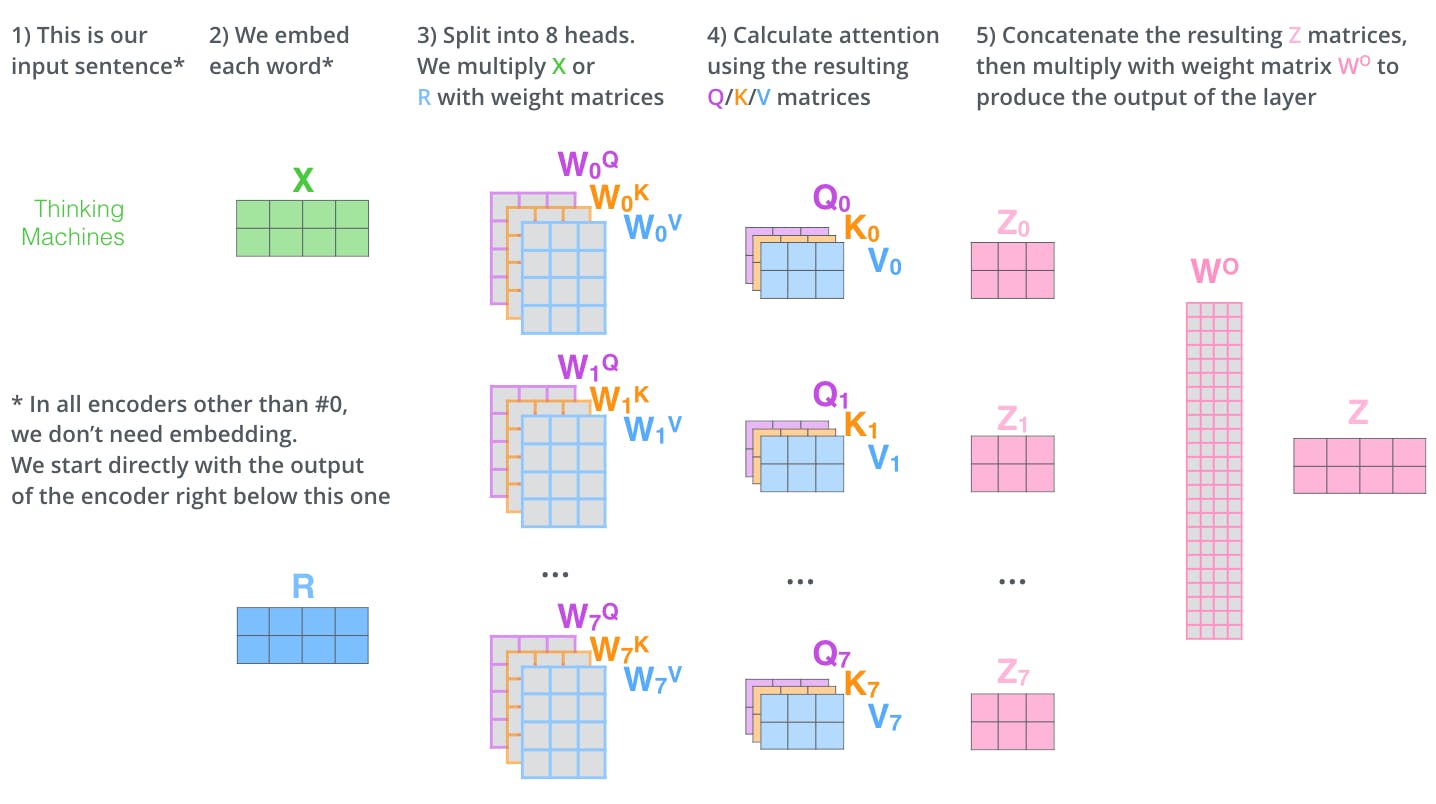
- Self Attention There are various steps in Self Attention, which we have discussed below. Self Attention is the function used in Research Paper for translation.
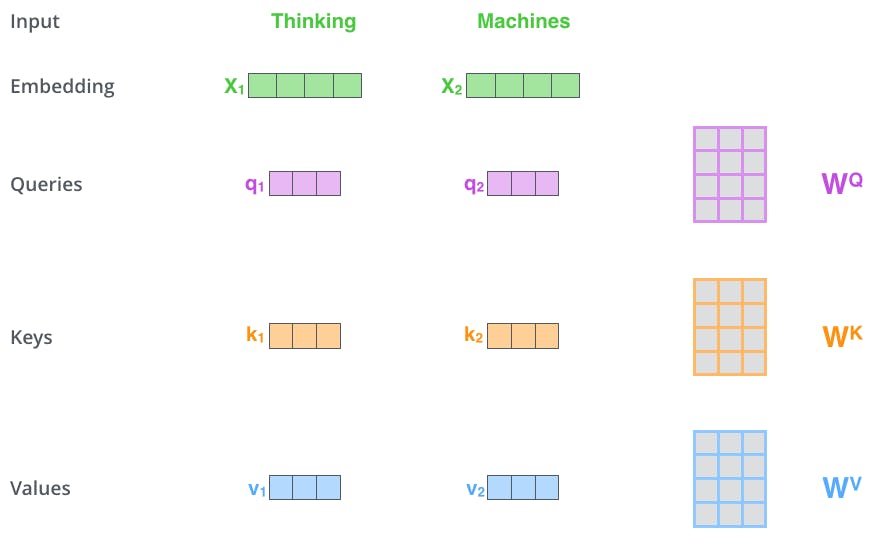
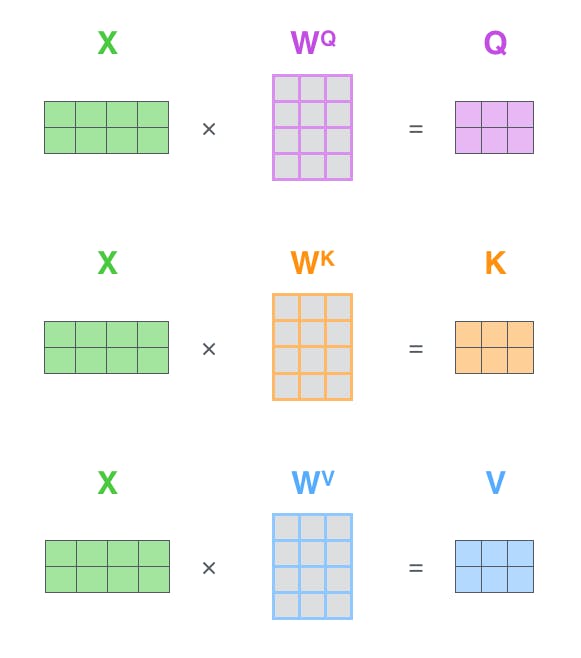
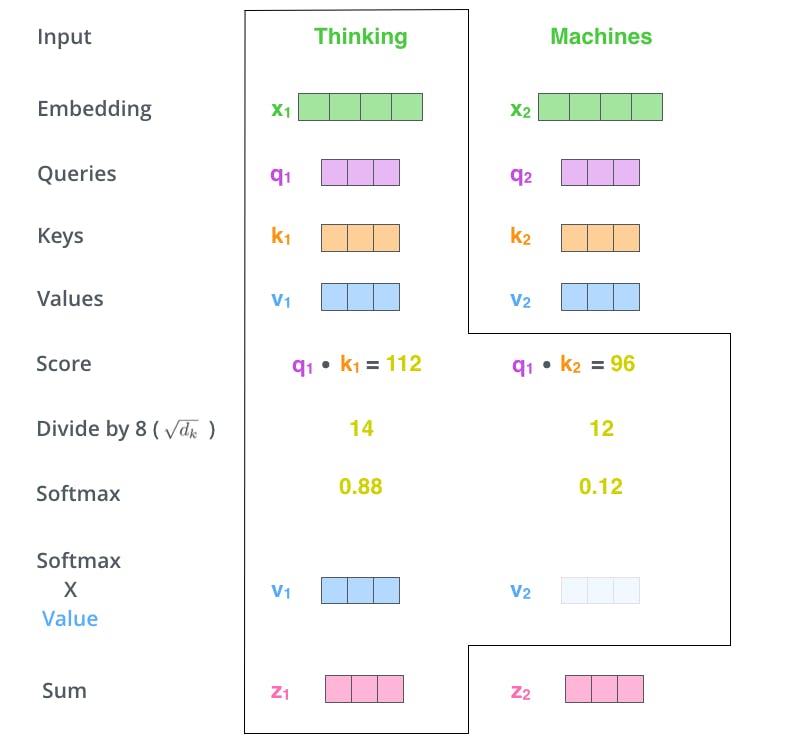
First Step, We have to create three vectors named Query, Key and Value for each encoding vector input, which can be created by multiplying **input vector and respective weights for query, key and value** which are randomly initialised with values between 0 and 1.
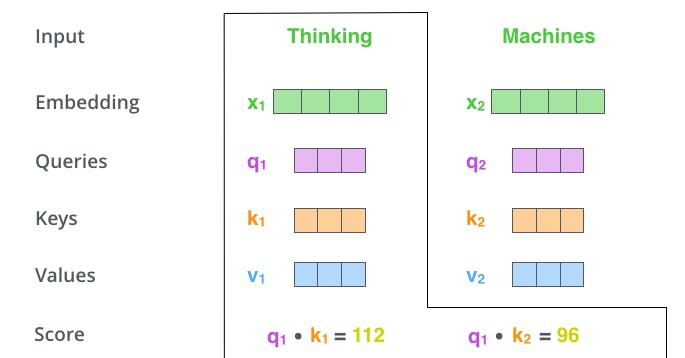
Second Step, Calculate the Score by taking the dot product of the query vector with the key vector of the respective word we’re scoring.
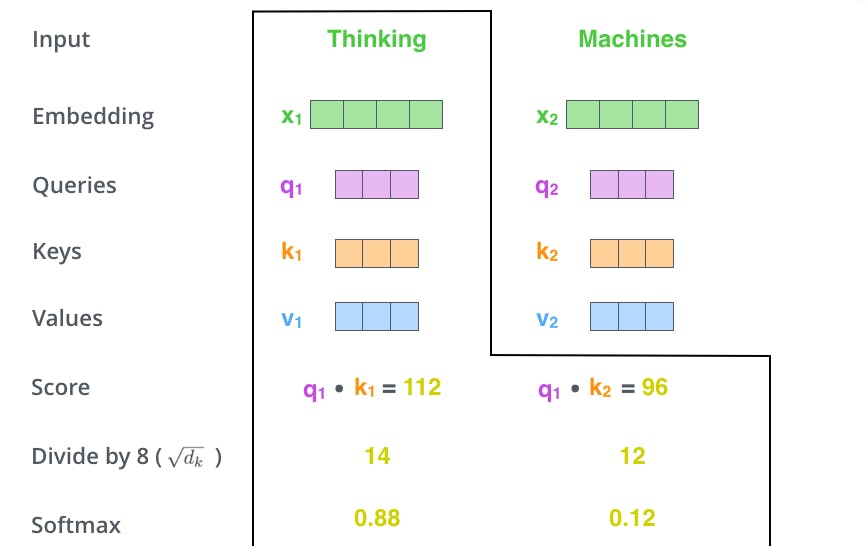
The Third and Forth steps are to divide the scores by 8 (the square root of the dimension of the key vectors used in the paper – 64. This leads to having more stable gradients.). After that results are passed to Softmax function. Function normalises the score and always results in between 0 and 1.
Softmax function shows the relevance of word at the position it is present .
In Fifth step, multiply the score of Softmax by each value vector. In Sixth step, sum up the weighted value vectors. This produces the output of the self-attention layer at this position for each word perform the same operation.
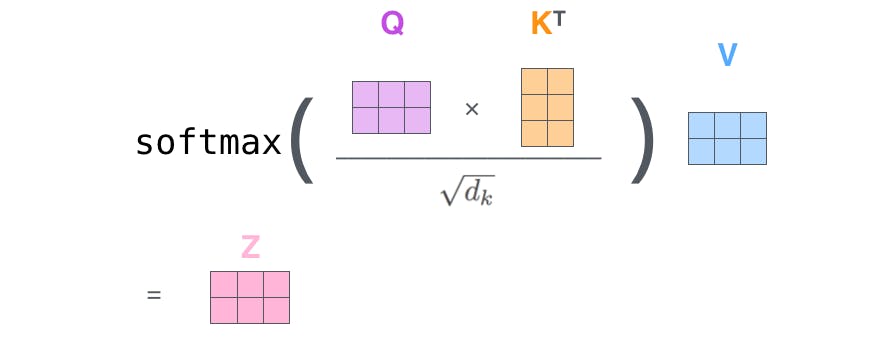
Positional Encoding
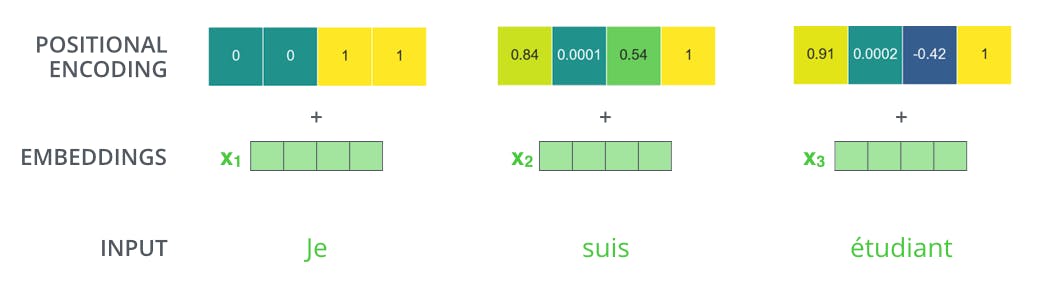
To address this, the transformer adds a vector to each input embedding. These vectors follow a specific pattern that the model learns, which helps it determine the position of each word, or the distance between different words in the sequence.
The intuition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Query/Key/Value vectors and during dot-product attention.
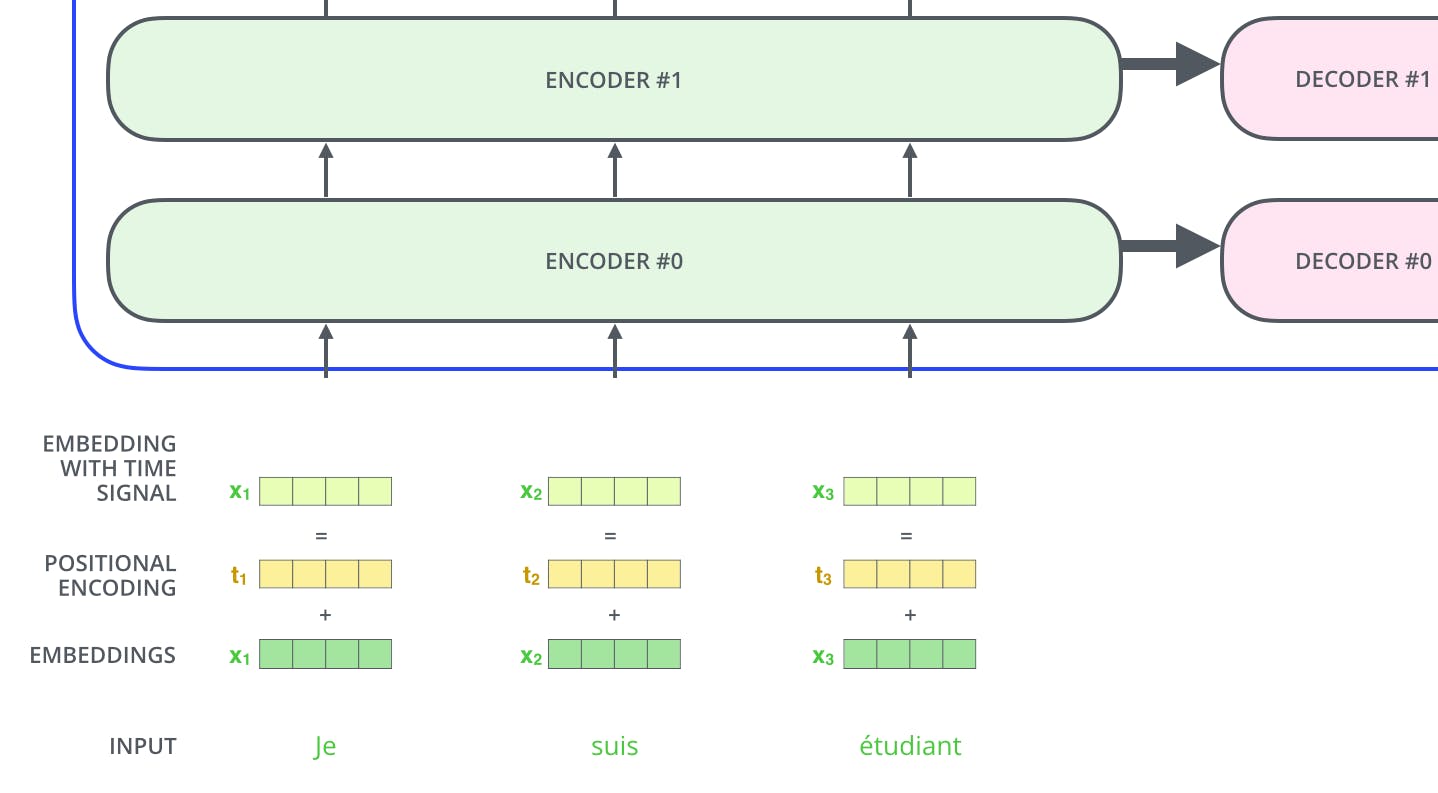
Here is a image which describes the whole Ender in just one shot, various components are shown
Decoders
Decoder are used to decode the value encoded by Encoders using Query/Key/Value vectors used by encoders. These are to be used by each decoder in its “encoder-decoder attention” layer which helps the decoder focus on appropriate places in the input sequence.
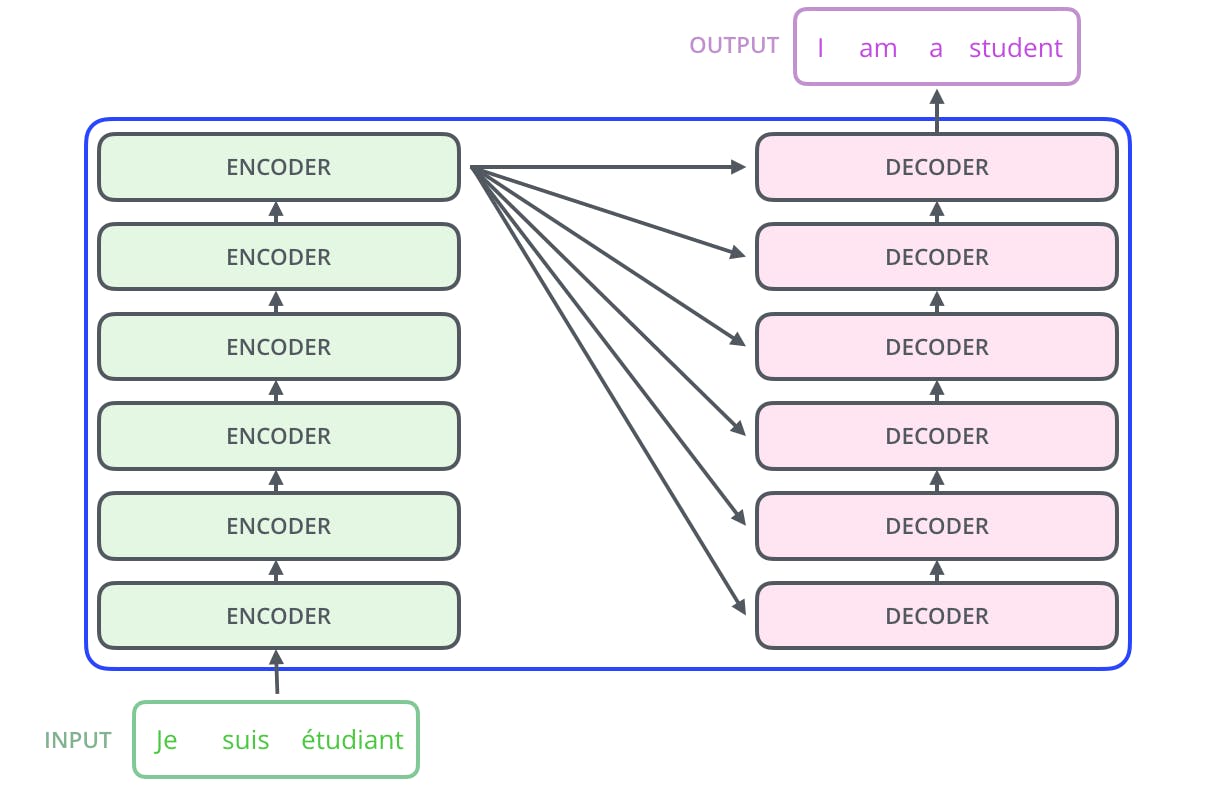
This would give you a quick glimpse of encoders and decoders together.

The various decoders outputs a vector of floats.
How do we turn that into a word?
There we use Linear layer followed by Softmax layer.
The Linear layer is simple neural network(consider it as ANN) which takes input as output of decoders and outputs a score for each word.
The Softmax layer then turns those scores into probabilities(between 0 and 1). Vectors with the highest probabilities will be chosen, and the word associated with it will produced as the output for each positional vector.
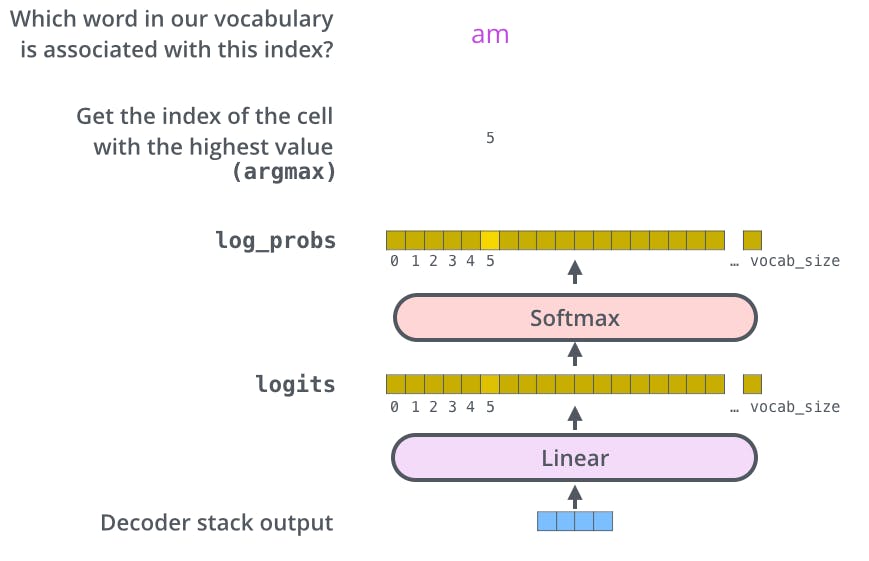
I hope the whole architecture of the Transformer model explained in the research paper is clearly understood.
Note:- All the images and gif are taken from Jay Alammer's GitHub post, do visit his Post. He has explained it so well.